Service-Oriented Architecture has proved its strengths in virtually all industries to produce scalable and evolutive systems. It enables the creation of systems capable of evolving and growing to operate on a large scale if necessary. Although the concept of service-oriented architecture encompasses several definitions, but its core idea of breaking a complex application into smaller, reusable and loosely coupled services has come a long way since the late 1990s.
We’ve embraced the concept from day one. And after three years, we now have about twenty domain-driven decoupled services structuring our backend applications. It allowed us to use the languages we liked — like Kotlin, Elixir — and the tools we wanted — like Event Sourcing — for the task at hand. Thanks to this choice of architecture, we were also able to put in place the tools we wanted to work with, such as event sourcing (keeping track of all the events that modify the state of a given application).
But having multiple services comes with its own challenges, the first one being how to make services communicate with each other? There are a lot of strategies out there, and this article is a return on experience on the ones we use at Memo Bank.
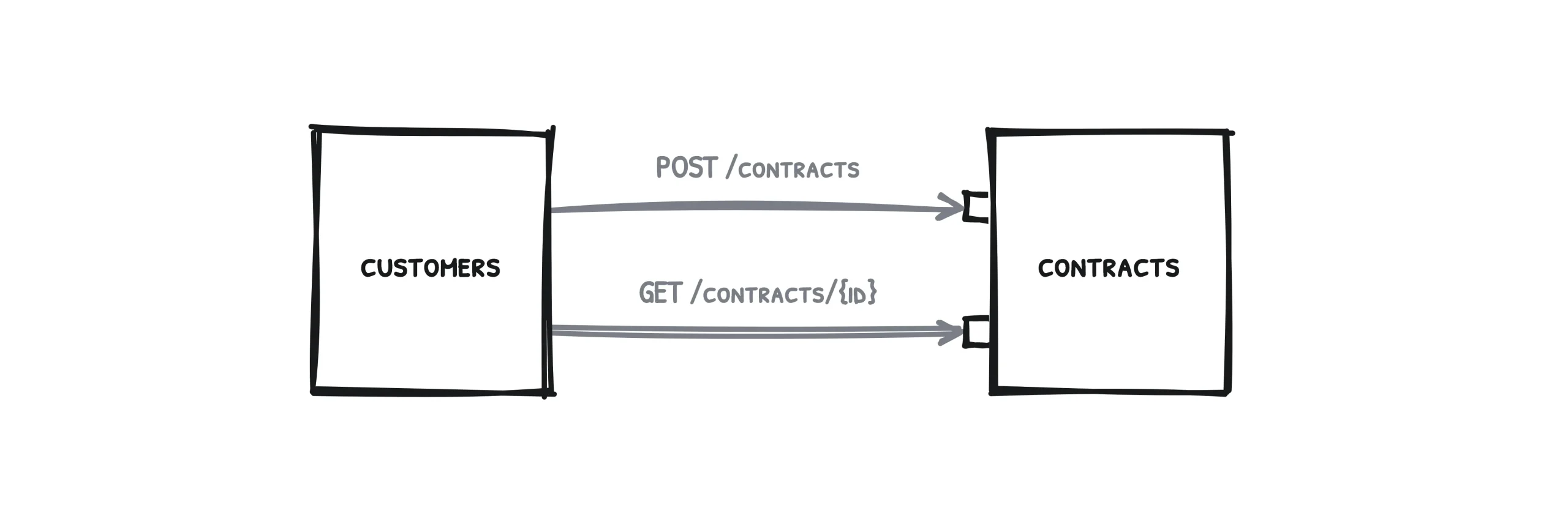
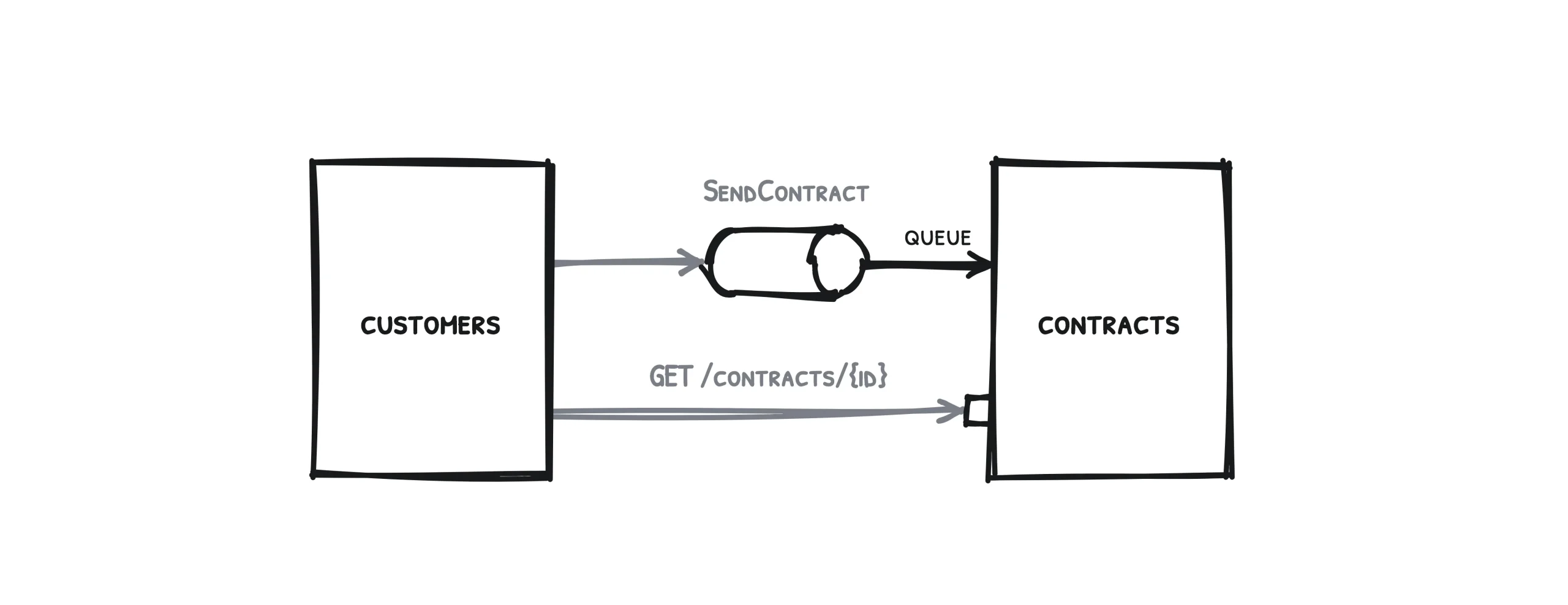
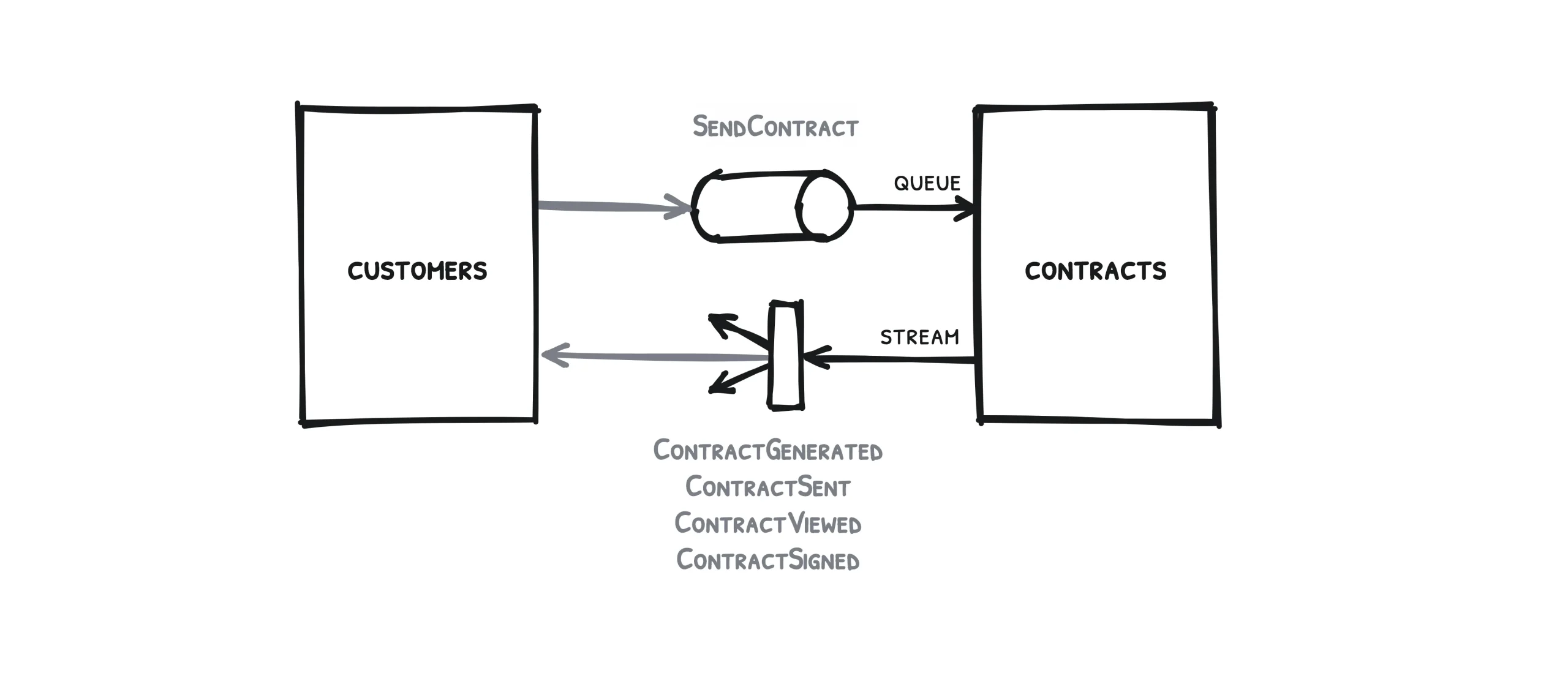
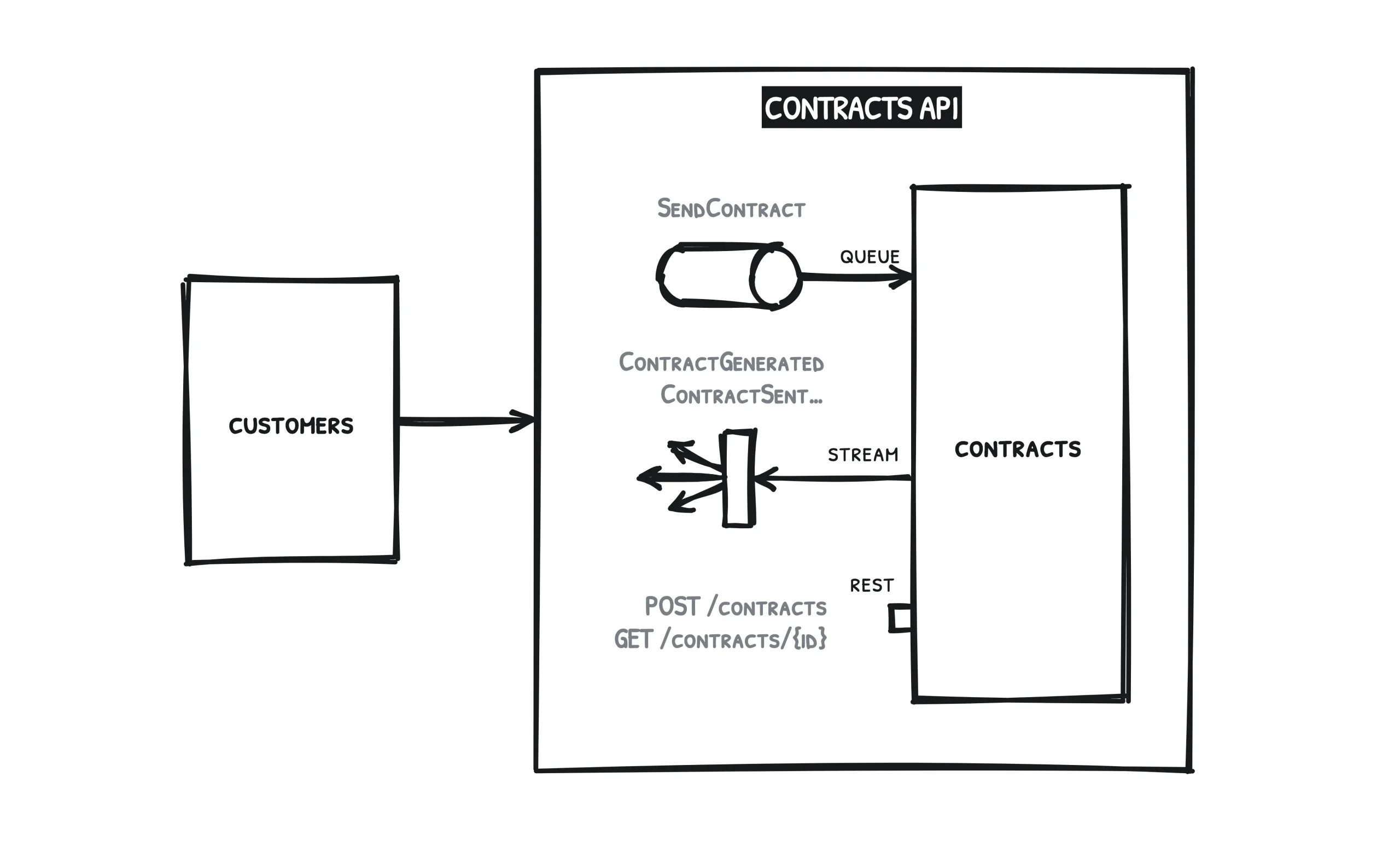
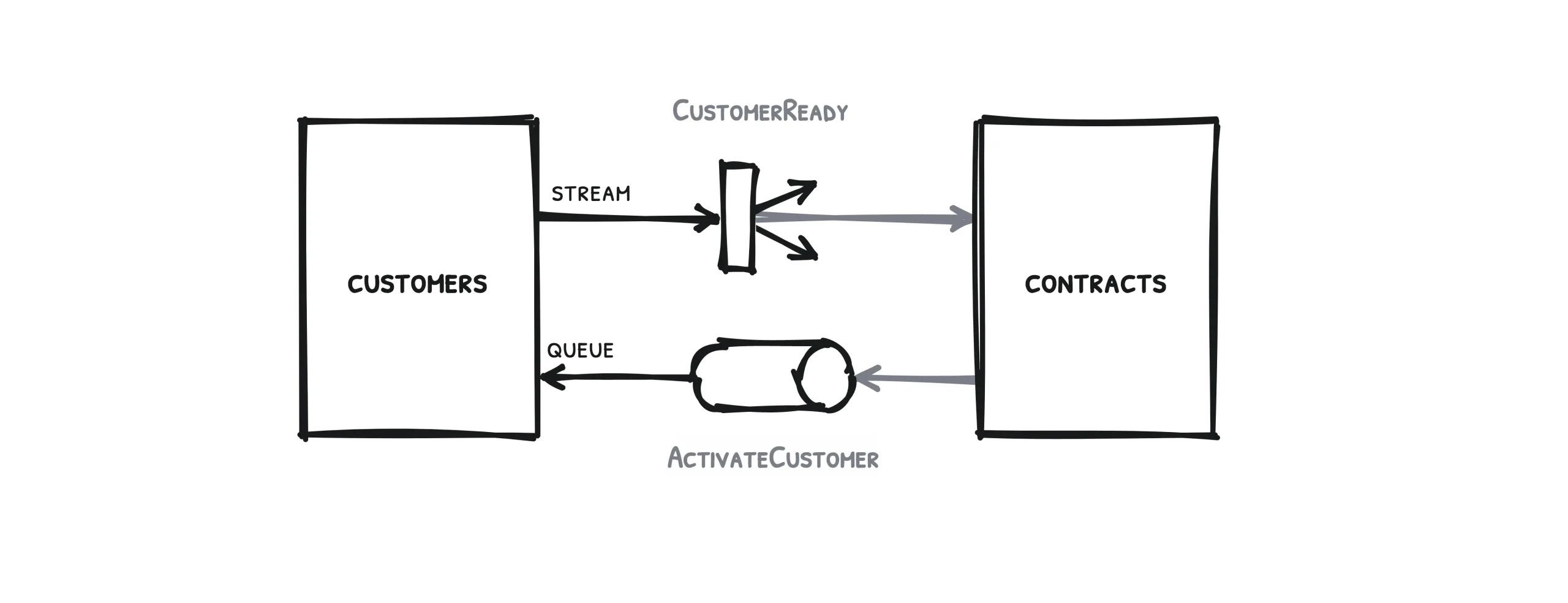
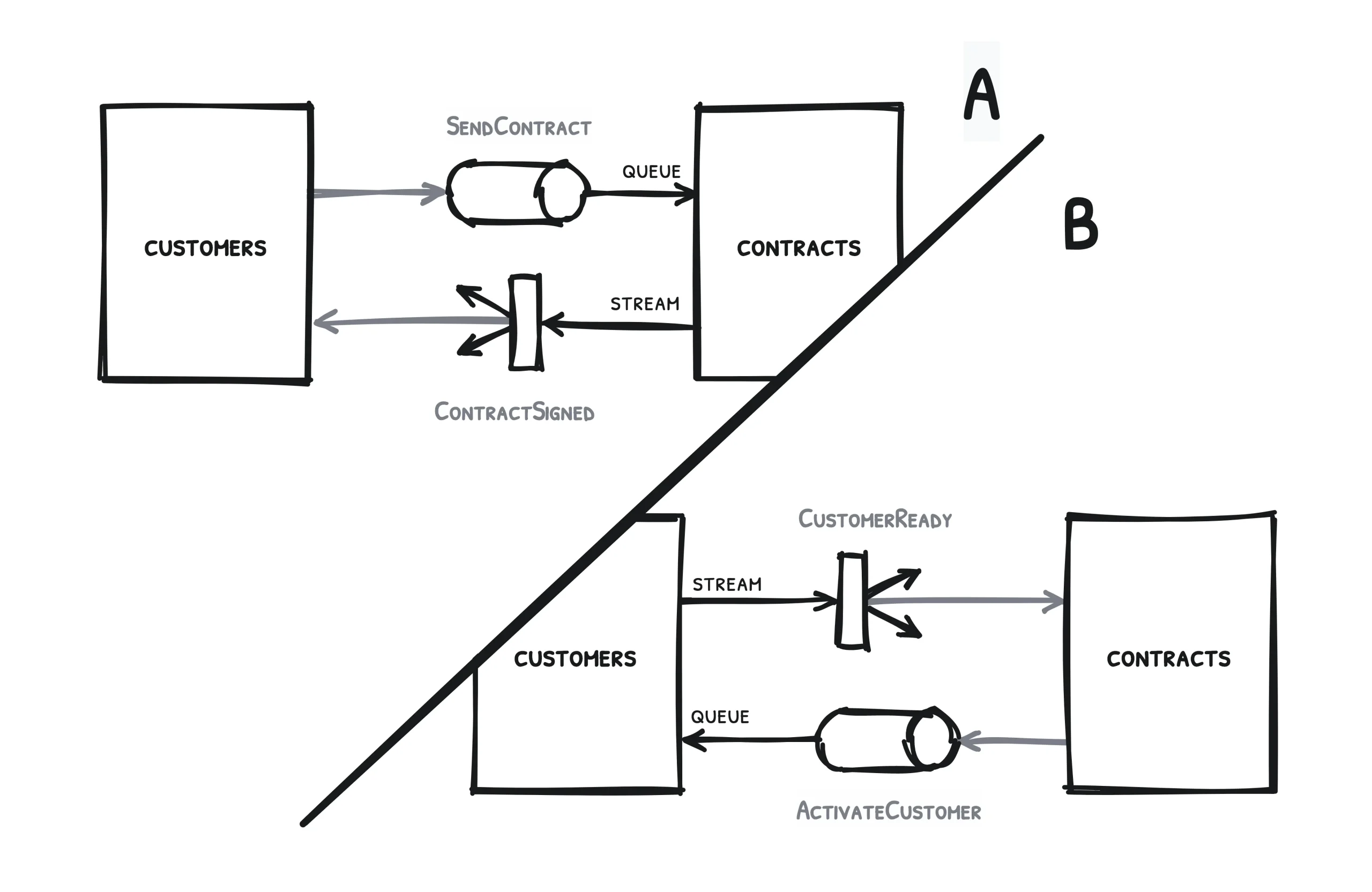
Let’s begin with two services and this simple use case as an example: