L’architecture orientée service (Service-Oriented Architecture) a fait ses preuves dans pratiquement tous les secteurs. Elle permet de créer des systèmes capables d’évoluer et de grandir pour fonctionner à grande échelle si besoin. Bien que la notion d’architecture orientée service recouvre plusieurs définitions, l’idée selon laquelle une application complexe peut être décomposée en sous-parties autonomes a fait son petit bout de chemin depuis la fin des années 1990.
Chez Memo Bank, nous avons souscrit aux principes de l’architecture orientée service dès le départ, dès nos premiers développements. Trois années plus tard, nos applications backend s’appuient sur une vingtaine de petits services, plus ou moins dépendants les uns des autres. Opter pour une architecture orientée service nous a permis de manipuler des langages qui nous sont chers, comme Elixir et Kotlin. Grâce à ce choix d’architecture, nous avons aussi pu mettre en place les outils avec lesquels nous voulions travailler, comme l’event sourcing (le fait de garder une trace de tous les évènements qui modifient l’état d’une application donnée).
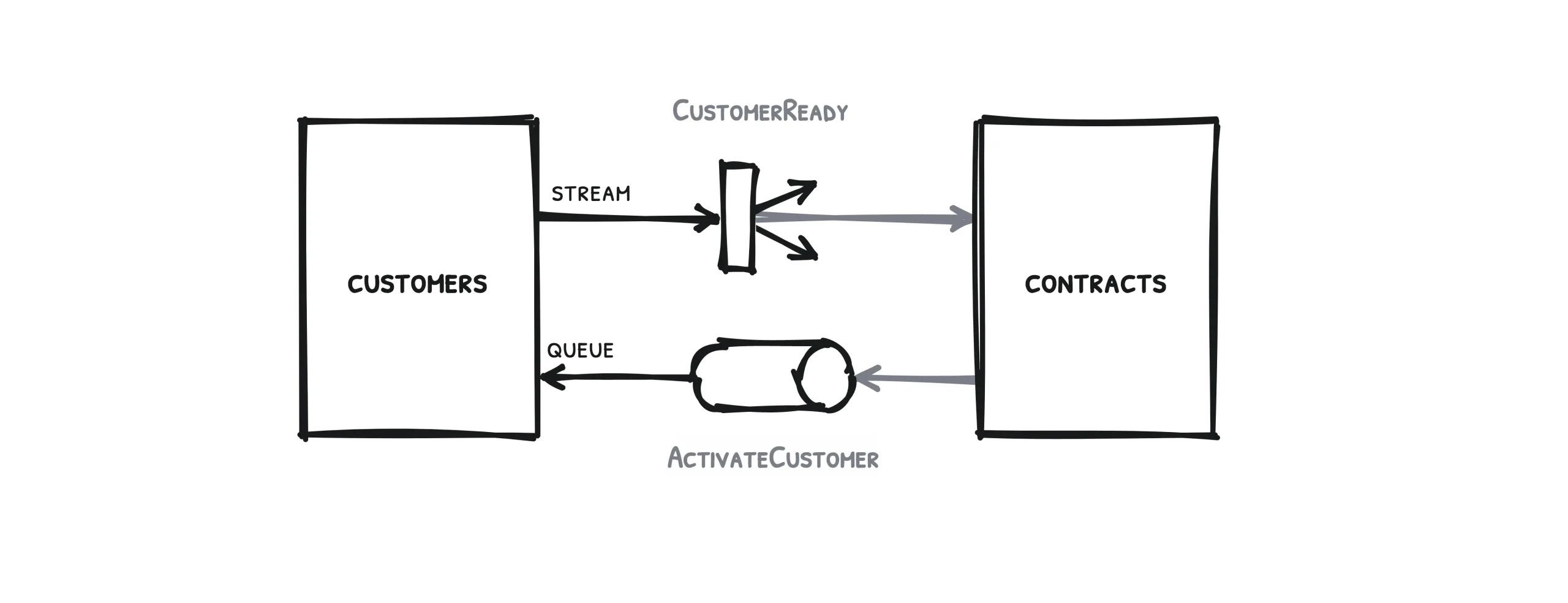
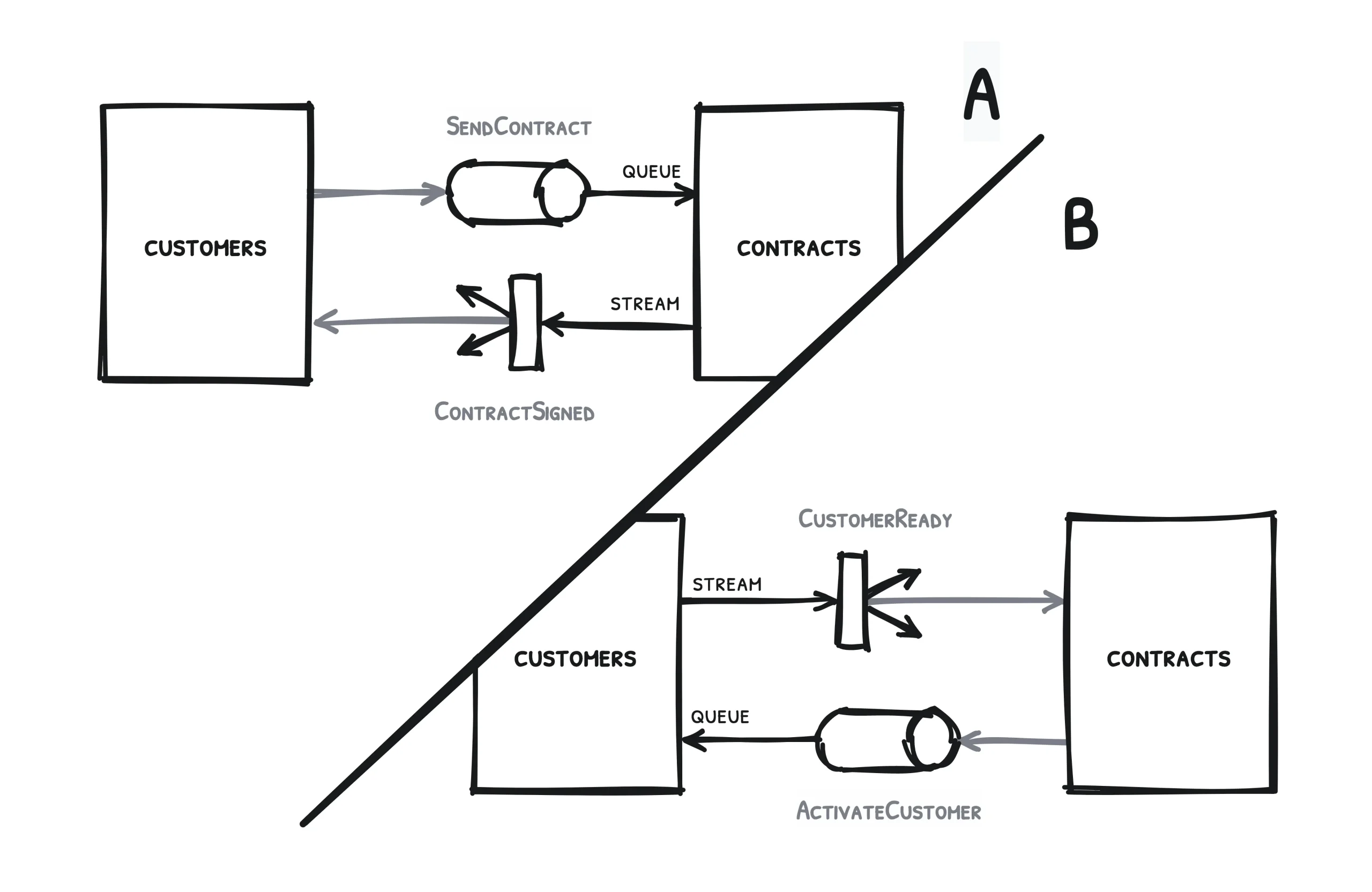
Avoir plusieurs services à notre disposition nous oblige à nous poser plusieurs questions, à commencer par : comment faire pour que nos différents services se parlent, discutent, communiquent entre eux ? Bien sûr, plusieurs personnes ont déjà apporté plusieurs réponses à cette question ; dans les lignes qui suivent, nous allons ajouter notre réponse à la pile de réponses existantes.
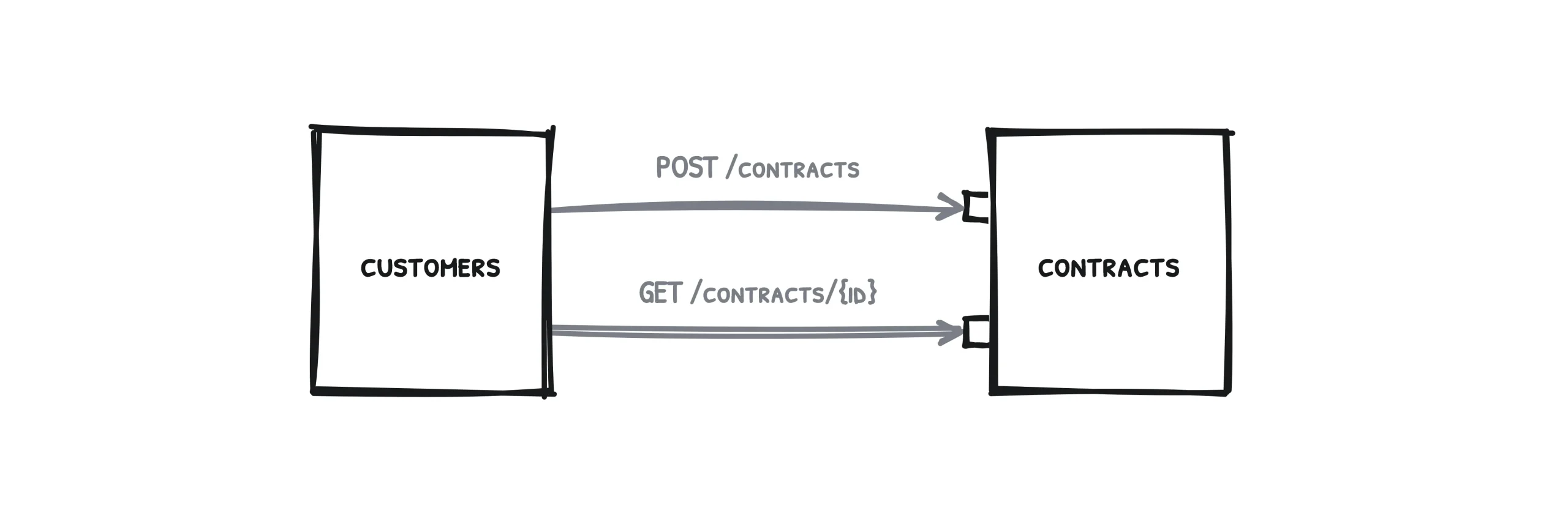
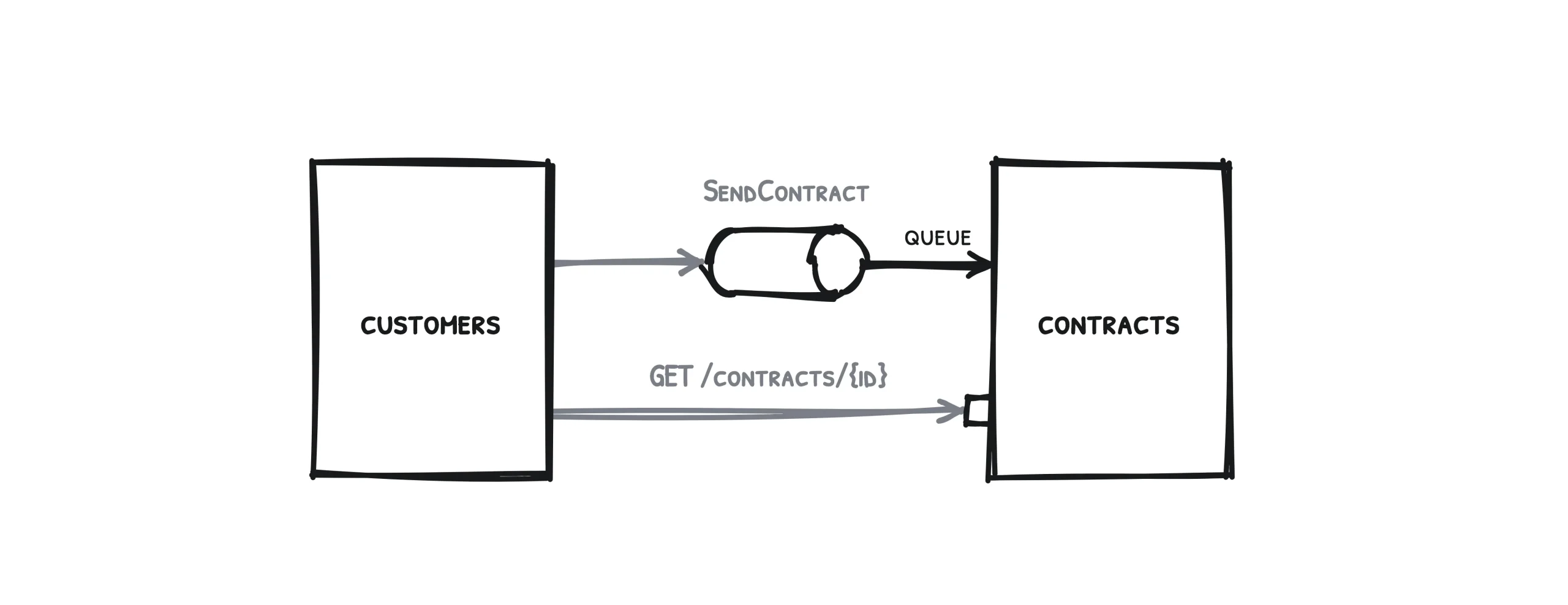
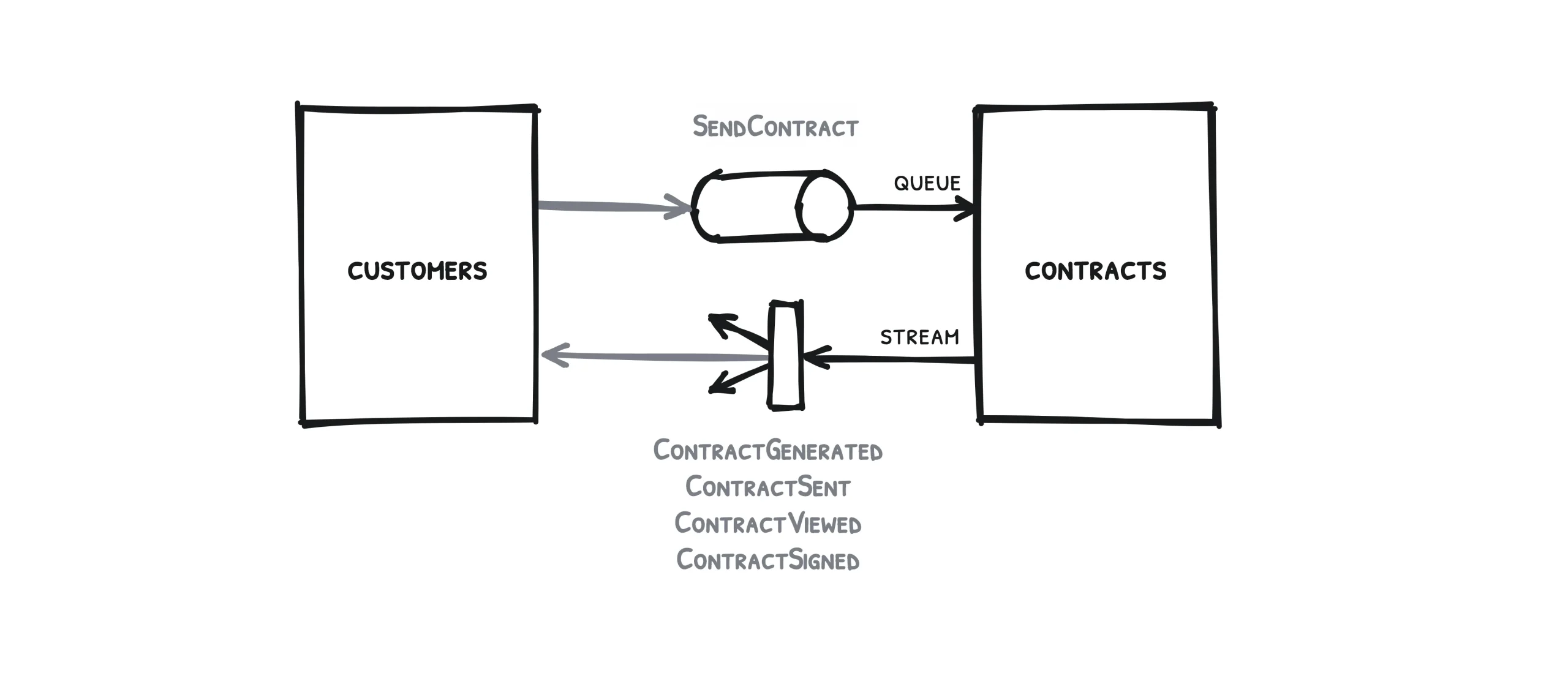
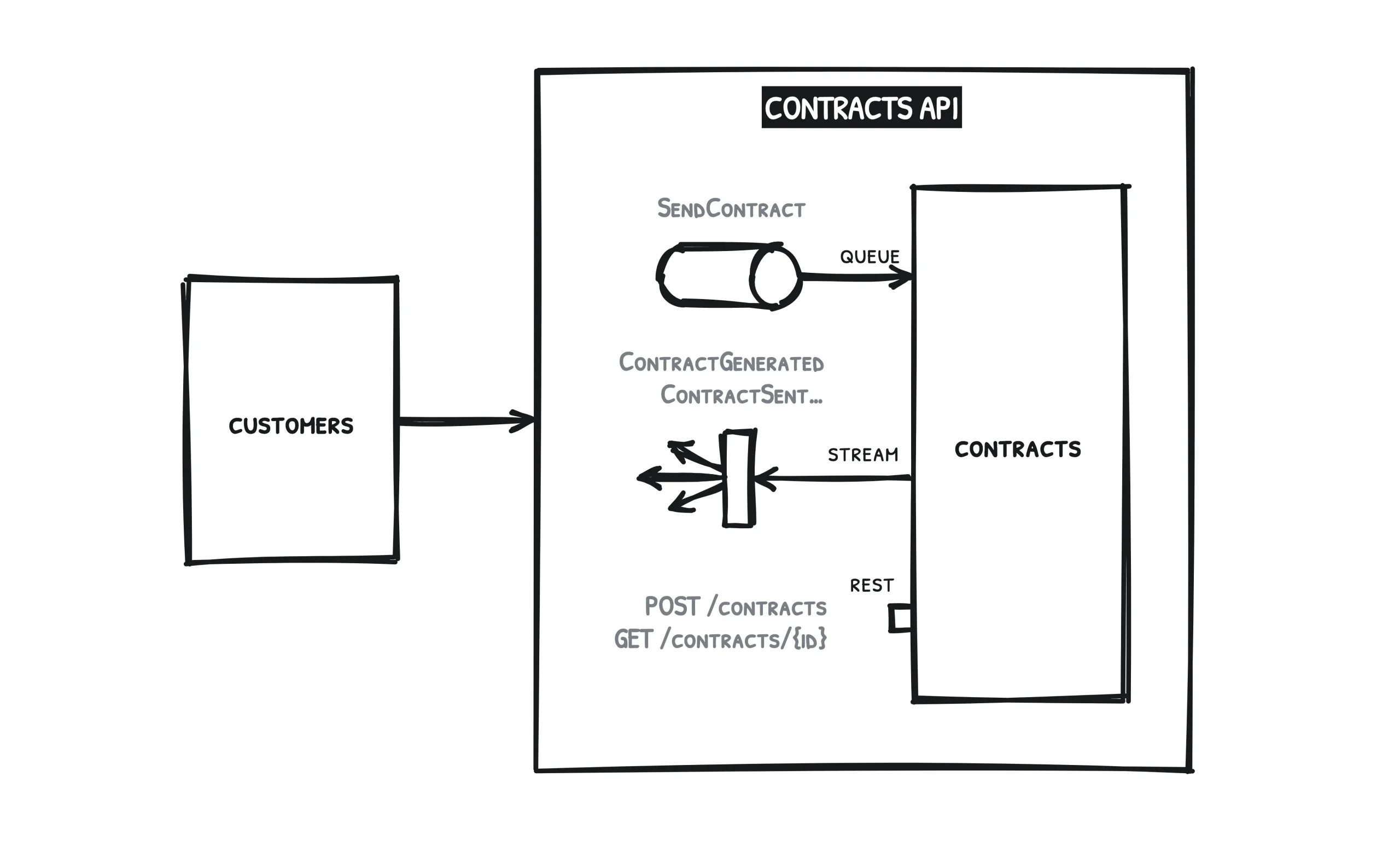
Pour commencer, prenons un cas de figure simple, une situation qui ne mobilise que deux services.